Introducing the Design for Stargate v2
When we announced Stargate v2, we mainly focused on the “why” behind the change. In this post, we’ll dive into the “how.”
Like all things in software engineering, arriving at this point was an iterative process. We’ll show you some of the designs we considered before landing on the one we propose today.
For context, we had a few different criteria in mind while reviewing each of these designs:
- Ease of contribution: We wanted to make sure that whatever change we made resulted in it being easier for both new and existing contributors to work with Stargate.
- Deployment flexibility: The ability to scale components independently was important to us, but we recognize that not everyone will need this and would instead prefer only one or two containers running.
- Ongoing performance: Of course, we also wanted to be sure that neither of the above changes came at the cost of latency, so we also wanted to ensure that the potential design would still be performant.
With that said, let’s get into the designs.
Considered designs
Not every idea can be a winner, and we abandoned our fair share of ideas during this design process. Here we’ll discuss some of these runners-up and explain why they didn’t make the cut. All of them share one thing in common: they assume deployment on Kubernetes.
Design 1: Separate everything
One of our ideas was to go in the opposite direction of where Stargate is currently. In this design, we’d switch from a “shared everything” approach to a “shared nothing.” Instead of everything running within the same JVM and connected using OSGi, each component of Stargate would be its own .jar capable of running in a dedicated container. The diagram below illustrates what this new architecture would look like.
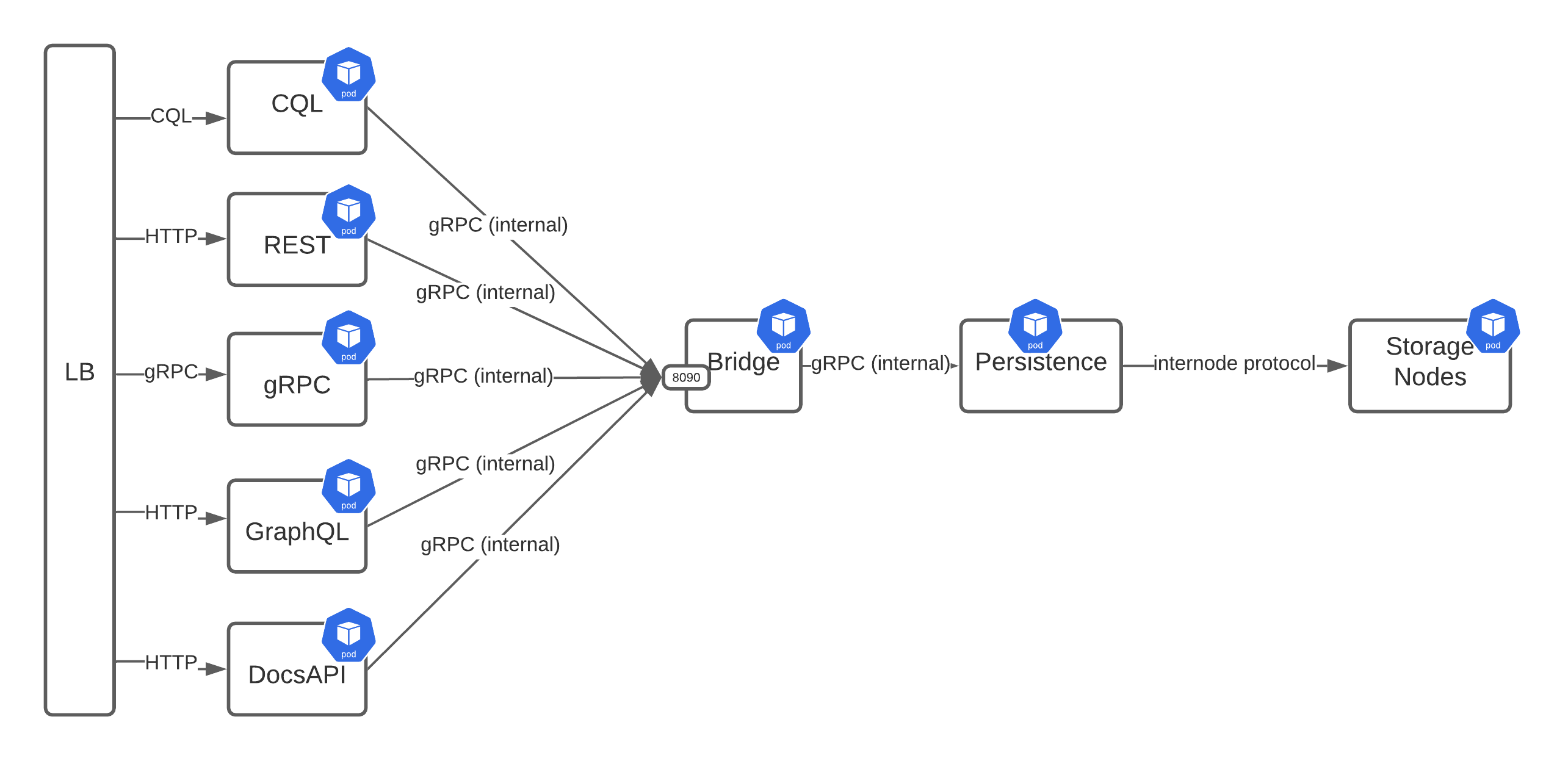
From left to right, here’s how it would work:
- A request would come in through the load balancer and then be routed to the proper user-facing service based on routing rules.
- Each service would be responsible for transforming its request into a gRPC payload that it would pass on to an internal gRPC (i.e. the “Bridge”).
- The Bridge would apply all cross-cutting concerns, like authentication and authorization, before passing the request along to the persistence service again over gRPC.
- Finally, the persistence would take the gRPC payload and transform it into CQL that could be processed and coordinated to the underlying storage nodes.
One benefit of this approach is that it provides flexibility for scaling and deployment. For example, if you don’t need the REST API then you would have the option to not deploy that pod. Likewise, for scaling, if you had more GraphQL traffic than Document API, you could add more GraphQL pods without changing the other deployments.
An immediate downside to this approach was for CQL, since those requests would need to be transformed from CQL frames to gRPC and then back to CQL. Given CQL’s latency-sensitive nature, we felt the additional overhead of multiple serialization and deserialization would be unacceptable.
Furthermore, this approach would require creating a new schema definition language to transport the requests between services. Although this would certainly be helpful for services that operate at a higher level than plain CQL (like the Documents API), we thought it was unnecessarily complex.
Design 2: Using CQL to communicate
The next option we considered was similar to the “shared nothing” design, but differed in that it used CQL as the communication protocol.
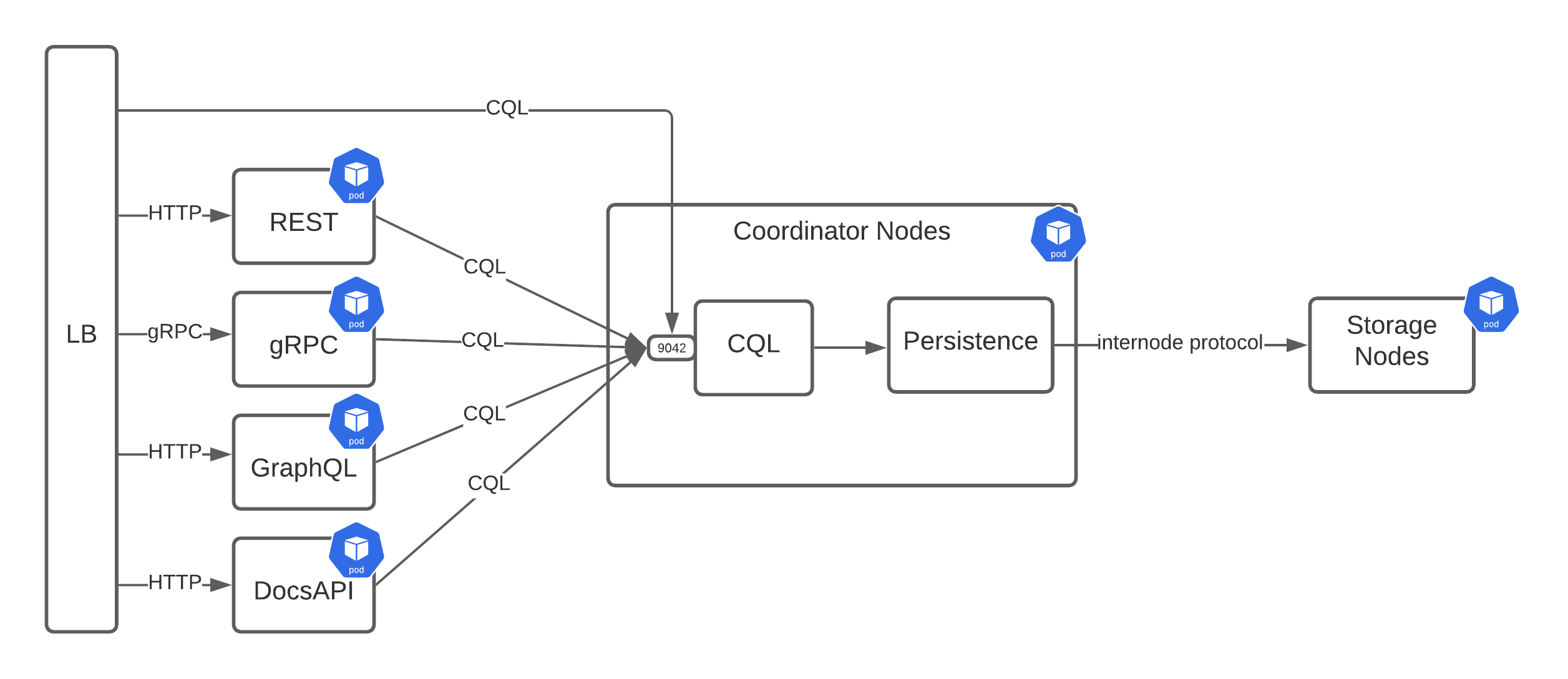
In this design both the CQL and persistence services would share the same container to reduce CQL latency, but the other services would be separated. For communication, each service would accept its request and then transform it into a CQL statement, which could be sent back to the CQL service via a driver.
This seemed like a promising approach since all of the current services are written in Java, which has a robust CQL driver. Except for the requirement of a driver introduces three potential issues:
- Stargate is written in Java, but we welcome the possibility of services being written in other languages. Although this means your language of choice would need a driver, and if it has a driver, it needs to be in a usable state.
- Having a driver bridge the communication gap between user-facing service and persistence creates some authentication issues. Since drivers tend to be session-scoped with a username and password, each service would need to create a new session for each request. Alternatively, there would need to be a system user for the services, which would then need to execute the queries on behalf of the user initiating the request.
- Even though most of the services are a one-to-one translation to CQL, there are occasions when this isn’t the case, so it would require making several requests from the service to persistence.
Design 3: Multiple bridges
One of our next ideas was a hybrid of the previous two. In this design, the simpler services that map more readily to CQL would take one path to the persistence service, while the others would take a different path.
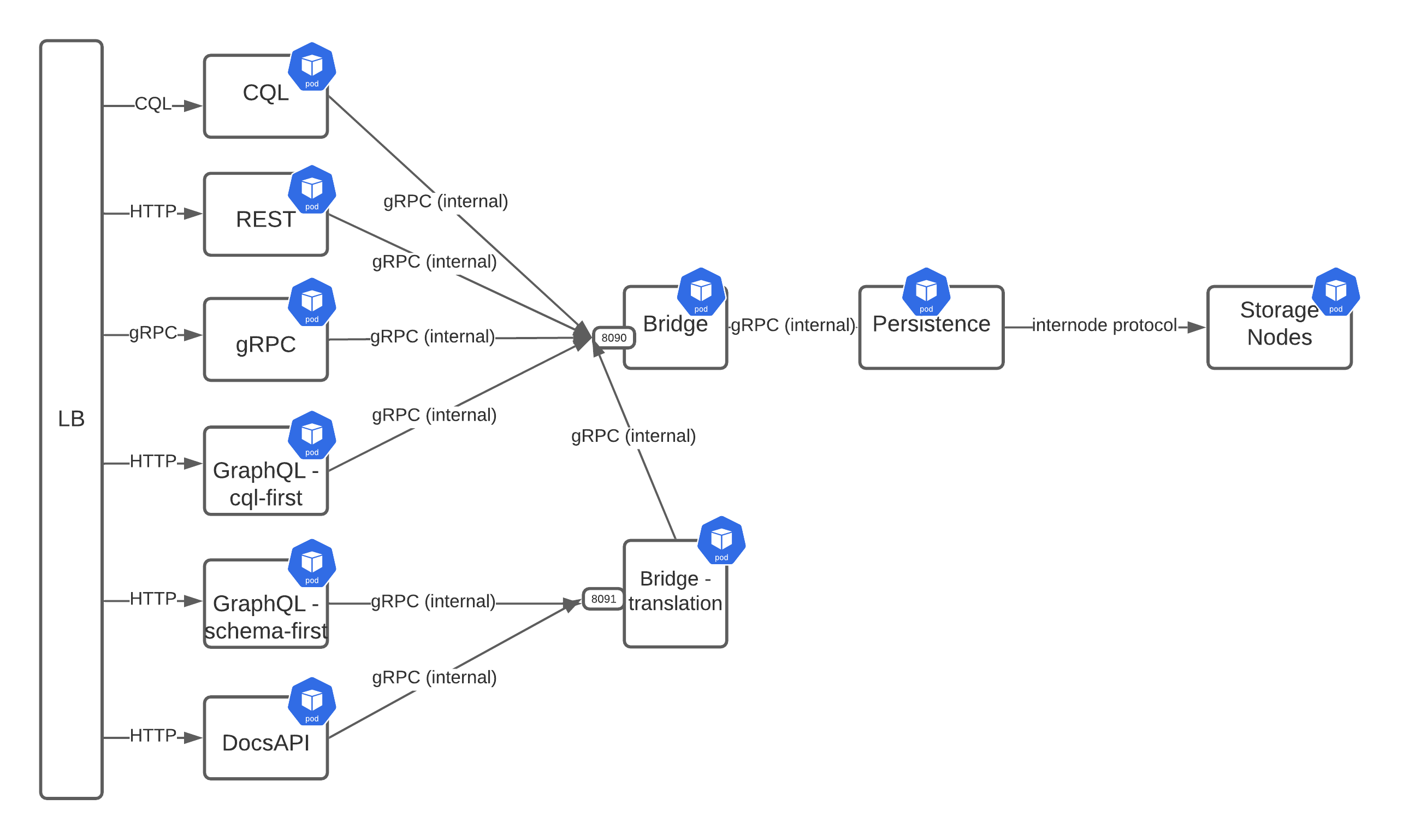
As shown in the diagram above, we have now gone from one to two Bridge pods and split up the GraphQL service. At the top half of the diagram, things have stayed largely the same in that services that map cleanly to CQL transform their requests into a gRPC payload and then pass that to the Bridge. Where this diverges is the “not directly CQL” services, which now go through a different Bridge that translates the requests into something lower-level before passing them along to the primary Bridge service.
One of the benefits of this design is that it removes the complexity of translating requests into gRPC from the external services and pushes it down into a centralized location. The translation Bridge can take the customized requests from both the Documents API and the schema-first version of GraphQL and transform them into simpler gRPC payloads that the inner Bridge service can process.
That being said, this design still suffers from the same downside of the previous design where it has several layers of translation and adds yet another layer for two of the services.
Meet the winning design
After weighing the pros and cons of the other potential designs, we finally settled on what we believe is the best option for Stargate v2. Take a look at the diagram below.
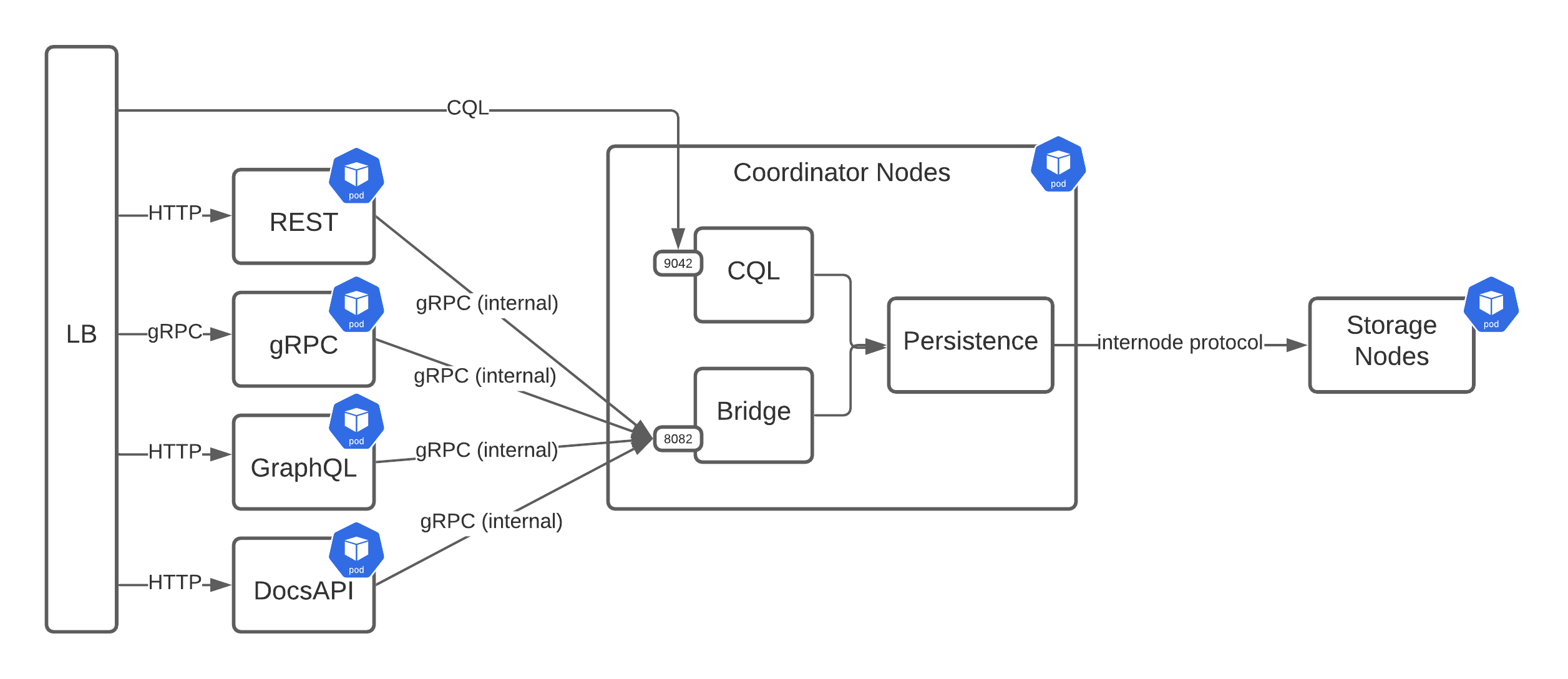
This design is similar to the earlier ones where the user-facing services are sitting behind a load balancer and communicating with the persistence service via gRPC. Although a noticeable feature is the addition of a “Coordinator Node.” This new Coordinator Node pod will contain three different services that run together in the same JVM: CQL, Bridge, and Persistence.
Next, we’ll briefly explain how the services involved in this design will work.
Services
The services component of Stargate will be composed of the discrete, user-facing services running as independent pods. Each service will be responsible for serving requests on its respective interface by:
- Accepting requests
- Transforming them into CQL
- Passing them along to the Bridge via a gRPC request
- Transforming the gRPC response back into its format (like JSON or GraphQL) and returning the payload to the user
REST, GraphQL, and gRPC continue to convert their respective request types into CQL strings. The Bridge will then pass the CQL string to the persistence service for the query to be executed. Going through the intermediate gRPC provides the services with a gRPC interface (rather than relying on drivers) and takes advantage of cross-cutting functionality provided by the Bridge.
Bridge
The Bridge will be a gRPC service that connects the various user-facing services with the persistence service. Its responsibilities will be to accept gRPC requests while performing authentication and authorization.
This service will be implemented in almost the same manner as the user-facing gRPC. This service will live within the same JVM as the persistence service and support cross-cutting concerns, such as: authentication and authorization, pluggable request/response filters (e.g. encryption, data masking), and metrics.
As a cross-cutting concern, it makes sense to push authentication and authorization into this layer rather than expecting each service to reimplement the same functionality.
CQL Service
The CQL service will continue to function in the same way it does today. It‘ll be considered part of the Coordinator Node and live within the same JVM as the persistence service and Bridge. Since it’s part of the Bridge, it’ll also take advantage of the same cross-cutting libraries as the Bridge.
Persistence
There won’t be much difference in the persistence services that Stargate currently offers. They’ll still operate as coordinators and keep all their existing functionality. The primary changes will just be cosmetic, like removing OSGi (if necessary).
The Bridge will be packaged within each Persistence layer to produce deployable containers for each supported backend (C* 4.0, DSE 6.8, etc.).
REST, GraphQL, and gRPC services
The current rest-api module will be refactored to a separate microservice that uses the internal gRPC API of the Bridge. Dependence on OSGI will be removed — although we’ll likely reuse the health checker module for this and the other HTTP-based API services to provide endpoints for liveness/readiness.
The REST API service will continue to support both the REST v1 and v2 APIs as there’ll be no API contract changes. The current GraphQL and gRPC API implementations will be factored out from their current places into separate microservices that use the internal gRPC API, and we’ll remove the dependence on OSGI.
Document API service
The current Document API implementation will be moved from the rest-api module into a separate microservice that uses the internal gRPC API. Dependence on OSGI will also be removed.
Because the Document API operates at a higher level than REST or GraphQL, it won’t follow the same pattern as those two services. Instead, it’ll need to either pull back more data than it needs and perform filtering on its side or send a different sort of payload to the Bridge, which is then interpreted and executed. An example of this payload would be an OR query. Both sides have their benefits. By pulling back more data than necessary reduces the complexity of the Bridge and moves the resource penalty (high memory usage) to the Document API service.
On the other hand, if we were to handle this on the Coordinator Node side we would then be able to reuse this functionality in other services. An application of this would be to add ORs or JOINs to GraphQL. We’ll resolve this question based on further testing as we progress.
Load balancing, authentication, and other cross-cutting concerns
We don’t assume usage of any particular ingress but encourage its use. The intent is to be compatible with whatever load balancer is used, be it Nginx, Envoy, or HAProxy.
For HTTP services we could move some of the cross-cutting functionality into a load balancer by exposing endpoints for rate limiting and ext_authz. But we would then leave it up to each user to implement this for their particular load balancer (assuming that their load balancer supports that functionality). For CQL, we still need to implement this logic within Stargate since load balancers wouldn’t be able to act on the binary protocol.
Authentication and authorization will continue to be pluggable as it is today. Although we include some base implementations, it’ll still be possible to support other methods by implementing the necessary interface.
Deployment considerations
Breaking apart Stargate will require changes to how it’s deployed, meaning we’ll need to create a Helm chart. As we iterate, this chart can become more advanced and allow for a more customizable deployment (e.g. just REST or some other subset of services).
In the base case, the chart will deploy each of the user-facing services as a separate pod in addition to the Coordinator Node pod (persistence, CQL, and Bridge). For resource-constrained environments, where there’s a sensitivity to the number of pods, various combinations of pods and containers are possible. For one, it could maintain the same setup as exists today by placing all of the containers in a single pod. Another setup could be two pods: one for the Coordinator Node and another for the services.
Final notes
We believe that the changes proposed in this design will lead to a much better experience for those who contribute to the Stargate project and those who run it to support their other applications.
Contributors will be able to quickly iterate on just the parts of the project they want without needing to understand as deeply the other components. Plus, it’ll open up the potential for newer Java versions and frameworks rather than Java 8 with OSGi or even a polyglot environment. Meanwhile, operators will have greater flexibility over their Stargate deployment and the potential for a lower-resource footprint when scaling to handle higher loads.
Overall, we’re excited about these new changes and look forward to working with the Stargate community to make this new design a reality. On that note, if you want to review this design and give us your feedback, join the discussion on GitHub.