The Stargate Cassandra Documents API
Because, sometimes, we just want JSON.
If you’re like me, when you start coding something new, you’re probably finding yourself working with JSON. Maybe you’re using Node.js or Python or any other dynamic language that uses JSON-like data natively or maybe you’re working with data that you’re pulling or serving from REST APIs. Either way, increasingly it seems like everything is ending up in JSON at some point. Most of the time, this isn’t a problem, it’s just the way that we build software these days. There’s just one problem, and that’s that Cassandra isn’t particularly good at JSON…
To double-click on that, the problem isn’t the JSON data format itself, although Cassandra doesn’t make JSON easy, it’s the way most devs use JSON when we’re building our apps. Iterative development means that plans change. The user registration form now needs a couple of more fields and the front-end dev went ahead and added them. That API I’m calling returns some extra data. Welcome to the loosely coupled world, it’s all fun and games until my app needs to send it to the database.
In the early days, Cassandra actually made this pretty simple to do, but as the project matured and added features like enterprise-friendly SQL-like query languages and better indexing, that meant that we needed the database to enforce a schema. Over time, it became harder and harder to use Cassandra for things like JSON and other document-oriented use cases.
Enter Stargate - if there’s one thing you should know about the Stargate team it’s that our personal mission is to make Cassandra easy for every developer. Figuring out how to give Javascript devs native JSON support without having to give up any of the reliability and scalability goodness of Cassandra was a challenge we couldn’t pass up.
This idea gave rise to the Stargate Documents API, which lets most Cassandra distros (Cassandra 3.11, Cassandra 4.0, and DataStax Enterprise 6.8), work with JSON through a REST API.
API features and design
As Jake Luciani and I started to create the bones of this API, we realized that Cassandra is nothing like a document store. Expressing data as rows is straightforward, but expressing trees of JSON data is really not. In addition, mapping that JSON data onto a table managed by Stargate and keeping both writes and reads reasonably fast adds an additional layer of complexity.
From here, we mapped out three main design components in order for this work:
- Modeling Documents in Cassandra
- Handling Reads and Writes
- Figuring out Deletes
The rest of this blog walks through how we approached each design and resolved some hiccups along the way.
Modeling Documents in Cassandra with Document Shredding
The first thing that we had to decide was the schema of the managed table that backs a document collection. Due to some great discussions with some Cassandra specialists, it was decided that when a user creates a document, a table will be created with a statement of the form:
create table <name> (
key text,
p0 text,
… p[N] text,
bool_value boolean,
txt_value text,
dbl_value double,
leaf text
)At this point is where we had to solve an unbounded data modeling problem. Because any JSON document that has a depth of [N] or less can be added to this table, each value in the JSON will get stored as a row in the table. So if I wanted to represent a document called “x” that has the JSON:
{"a": { "b": 1 }, "c": 2}The document would be “shredded” into rows looking like this:
| key | p0 | p1 | dbl_value |
|---|---|---|---|
| x | a | b | 1 |
| x | c | null | 2 |
For data with an array, such as:
{"a": { "b": 1 }, "c": [{"d": 2}]}there would be two rows, like so:
| key | p0 | p1 | p2 | dbl_value |
|---|---|---|---|---|
| x | a | b | null | 1 |
| x | c | [0] | d | 2 |
Array elements are stored with square braces in the column.
Handling Reads and Writes
The next problem that arose was that naïvely, updates to a document could require reading the document from the database, seeing what modification would have to be made, and then writing the updated data. This “read-before-write” process is a notorious source of performance and consistency issues in most data stores.
Therefore, we resolved to avoid doing any read-before-write operations at all costs.
An interesting implementation detail that came up is that when you write some data to a document, the resulting write operation is just a simple batch with some inserts and deletes. In some cases, this can cause the document rows in the database to show two different states for the same JSON field.
And, upon reading the rows out, the Documents API reconciles conflicting information by accepting the data that has a later Cassandra write time (much like Cassandra itself!).
This allows us to write data really quickly while not compromising too much in reads either, as the reconciliation does not happen often and is also quite fast. It also gives us a very important core principle to our basic write and read operations:
- Every write to a single document is a single batch of statements, and
- Every read from a single document is a single SELECT statement.
So writes and reads are squared away - but what about deletes?
Figuring out Deletes
Because of the distributed nature of the database, a deletion in Cassandra actually is very similar to an insert, but instead a “tombstone” is written at a particular write time to signify the death of a row.
Rest in peace… almost
Cassandra periodically (the frequency here depends on your compaction strategy and/or cluster load) does a compaction operation to remove tombstones and alleviate this pressure, so the only way to avoid overwhelming Cassandra is to make sure that the frequency of deletions is low enough.
This poses a problem for the Document API specifically because of arrays. Let’s walk through this one.
Imagine that you have an array at some key that is of length 100000. If you then issue a replace operation (via a PUT) and decide to replace that array with some other value, then all of those 100000 rows would be deleted, causing 100000 tombstones to be written. This is an enormous number of tombstones to be written in one operation, and if you do that just a few more times, Cassandra will likely get super slow. So the structure of the data in each table needed one last major modification.
We said before that array paths are stored in the database with square brackets; for example the element at index 0 would be stored as [0]. That would mean a deletion of 100000 elements would look like this:
DELETE FROM <name> where p0 in ('[0]', '[1]', '[2]', …, '[99999]')Causing 100000 tombstones to be written. Instead of doing that, we decided to pad all array elements with leading zeros, so the element at index 0 would instead be represented as [000000], and the element at index 99999 would be [099999]. Doing this allowed us to change the deletion statement to:
DELETE FROM <name> where p0 >= '[000000]' and p0 <= '[999999]'Which causes only a single so-called “range” tombstone to be written, instead of 100000 cell tombstones (note that greater and less than works on strings in Cassandra and will compare lexically). It also relaxes the array length limit to one million elements, which is pretty neat! The time series below shows how the old vs. new implementation might behave, if you performed compactions every week:
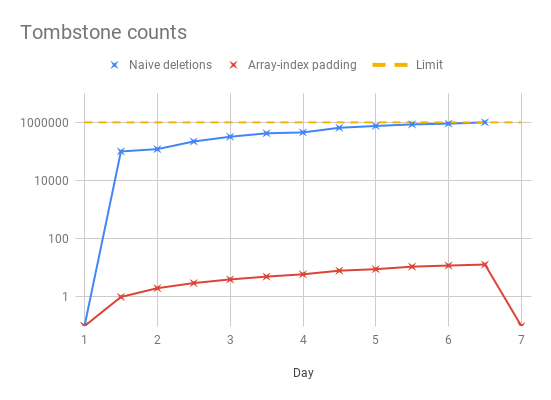
So the new strategy is just safer for deletions; it would require an incredibly large amount of deletion with the new strategy to even come close to the theoretical tombstone limits!
Preliminary Look at API performance
⚠️ Before starting on this section, we want to mention that benchmarking is a great tool, but does not necessarily represent how a system will behave under real load, out in the wild. We also haven’t done comparisons on the same hardware with other document stores…yet. Alright, let’s get to it!
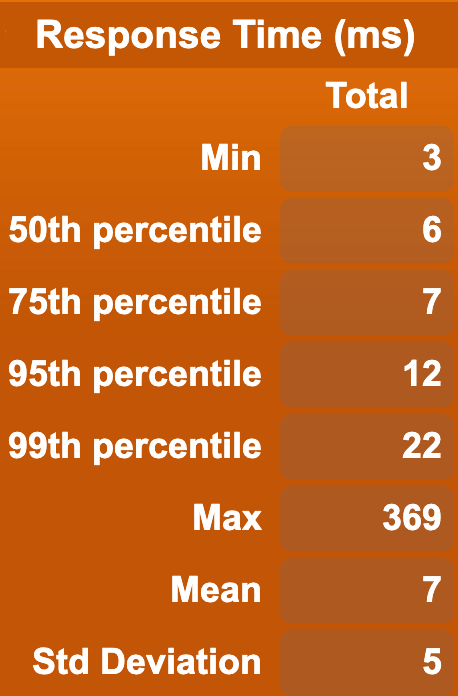
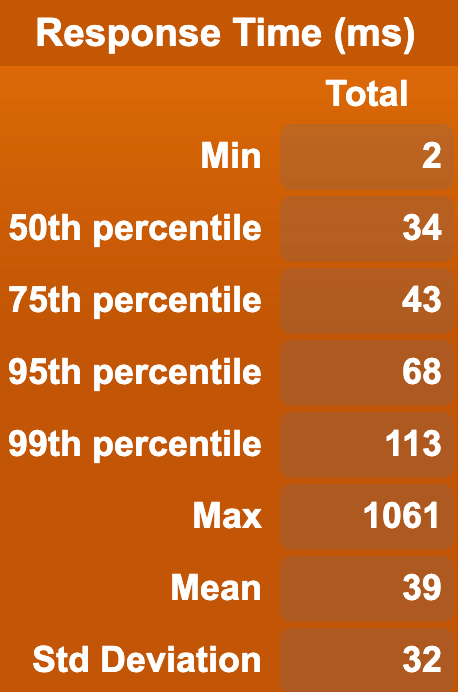
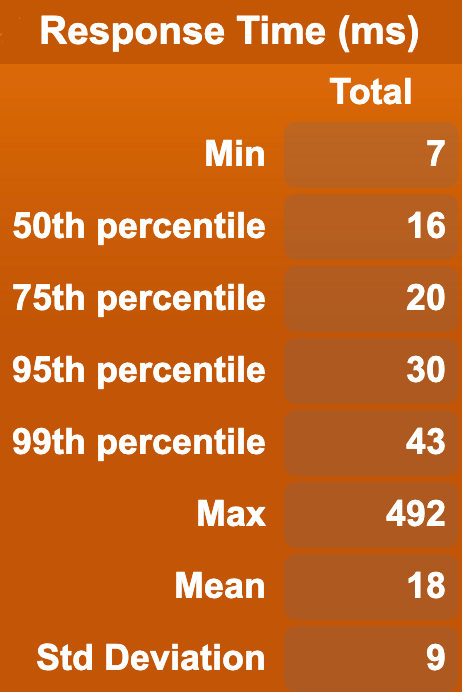
In order to test that the Document API is reasonably fast, we ran a benchmark test using a single Cassandra storage node and a single Stargate node (Stargate is the API that contains the Documents API). We then ran two different benchmarks, one that uses HTTP GET to repeatedly get random paths in a document, and another that performs HTTP POSTs repeatedly to create brand new documents. Each of these actions got run 100000 times, and here are two graphs of the results.
To keep things simple, as there is no baseline to compare things against just yet, the benchmark was performed using only one requester at a time, with light concurrency (10 users at once), and with more concurrency (100 users at once). Note that it’s expected with only one backend node that higher concurrency would cause degradation in performance; you should have multiple nodes to service that degree of concurrent requests!
Here are the results for reads:
| 1 user: | 10 users: | 100 users: |
|---|---|---|
 |
 |
 |
And for writes:
| 1 user: | 10 users: | 100 users: |
|---|---|---|
 |
 |
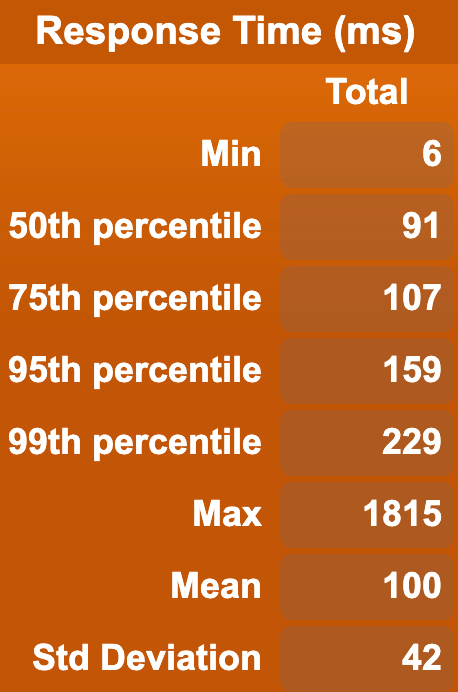 |
From the above, we can see that the API performs pretty well at a reasonable level of concurrency for our setup.
Final remarks
We hope you enjoyed taking this quick tour of the Documents API. If you are interested in using the API head over to Stargate.io for more information about how to use it in your own Cassandra distribution.
If you are interested in contributing to Stargate, which is entirely open-source, we have two places for you to join us:
- Come join our Discord Community to follow the latest with Stargate and get early access to new stuff
- For any issues or pull requests, come on over to our GitHub Repository
The APIs in Stargate are being actively developed, so we are hoping to be able to get back to you soon with news of even more improvements!