Hello GraphQL; meet Cassandra
Today, we’re happy to introduce a new member of the Stargate API family; say hello 👋 to GraphQL. This new API extension makes it easy to add a GraphQL API layer to any new or existing Apache Cassandra® database.
If you already know Cassandra and its data model, this first version of the GraphQL API in Stargate is for you. If you’re completely new to Cassandra and its query language (CQL), feel free to follow along, but you’re either going to need to brush up on the basics of Cassandra or wait until the upcoming releases that will give you the option of skipping CQL completely.
When Stargate’s GraphQL API is added to an existing Cassandra deployment, it scans the database and automatically creates HTTP endpoints with GraphQL queries and mutations for the objects that it finds in the database. New database tables can also be created directly via the API.
We’re just getting started with this new extension and we’d love to hear what you think. Read on to see the steps to get started and drop a comment on the GitHub issues labeled with “graphql”, post in the graphql-api channel on our Discord serever, or give us a shout on Twitter at @stargateio.
CREATE TABLE library.books (
title text PRIMARY KEY,
author text,
genre text,
year int
);mutation {
books: createTable(
keyspaceName: "library",
tableName: "books",
partitionKeys: [
{name: "title", type: {basic: TEXT}}],
values: [
{name: "author", type: {basic: TEXT}},
{name: "year", type: {basic: INT}},
{name: "genre", type: {basic: TEXT}}
])
}INSERT INTO library.books (
title,
author,
genre,
year
)
VALUES (
'Dune',
'Frank Herbert',
'Sci-Fi',
1965
);mutation {
dune: insertBooks(
value: {
title: "Dune",
author: "Frank Herbert",
genre: "Sci-Fi",
year: 1965}) {
value {
title
}
}
}SELECT *
FROM library.books
WHERE title='Dune';query {
books(filter: {title: {eq: "Dune"}}){
values {
title
author
genre
year
}
}
}How it works
Stargate’s GraphQL API is built using the GraphQL Java implementation and you can find the source code in the graphqlapi directory in the Stargate repo.
By default, the API exposes two HTTP endpoints. The first is at the /graphql-schema path and exposes an API for exploring, creating and altering the database schema. The second is at the /graphql/{keyspace-name} path and exposes an API for inserting, modifying, deleting and querying data.
Each of the mutations at the /graphql-schema path are built using the GraphQLFieldDefinition API from GraphQL Java and the generated fields mirror the Data Definition Language in Cassandra. Let’s look at an example of the createTable mutation below.
createTable(
keyspaceName: String!
tableName: String!
partitionKeys: [ColumnInput]!
clusteringKeys: [ClusteringKeyInput]
values: [ColumnInput]
ifNotExists: Boolean
)You’ll see that this has the keyspaceName, tableName, partitionKeys, clusteringKeys, values, and ifNotExists fields.
Each of the mutations and queries for Stargate’s GraphQL API follow this general pattern. If you’re interested in learning how this works in the Java code, hop down to the Deep Dive section of this blog or better yet check out the source code in the graphqlapi directory!
Get started
The easiest way to get your hands on the GraphQL API is to use the Stargate docker image and start the container in developer mode. There is also a built-in GraphQL Playground servlet to make it easy to test and tinker with your mutations and queries.
Set-Up: Get the image and authenticate. Then, hello GraphQL.
Step 1: Start Stargate coordinator and GraphQL API using Docker (https://hub.docker.com/u/stargateio)
We have instructions under the docker-compose that you can use to run Stargate with the Cassandra version of your choice. Tip: use one of the “developer mode” scripts for faster startup, for example:
git clone stargate/stargate
cd stargate/docker-compose/cassandra-4.0
./start_cass_40_dev_mode.shStep 2: Generate an authentication token from Stargate’s REST-based auth service using the default credentials. Note: these credentials should be changed for real environments.
curl -L -X POST 'http://localhost:8081/v1/auth' \
-H 'Content-Type: application/json' \
--data-raw '{
"username": "cassandra",
"password": "cassandra"
}'You should see this output, copy the token to your clipboard:
{"authToken":"{auth-token-here}"}Step 3: Insert your creds into your GraphQL Playground Access the GraphQL Playground in a browser: localhost:8080/playground
Paste your auth token as a header parameter in the HTTP HEADERS pop-up in the lower left hand corner of GraphQL Playground.
Your token needs to be in the following format in the header window:
{"X-Cassandra-Token": "{auth-token-here}"}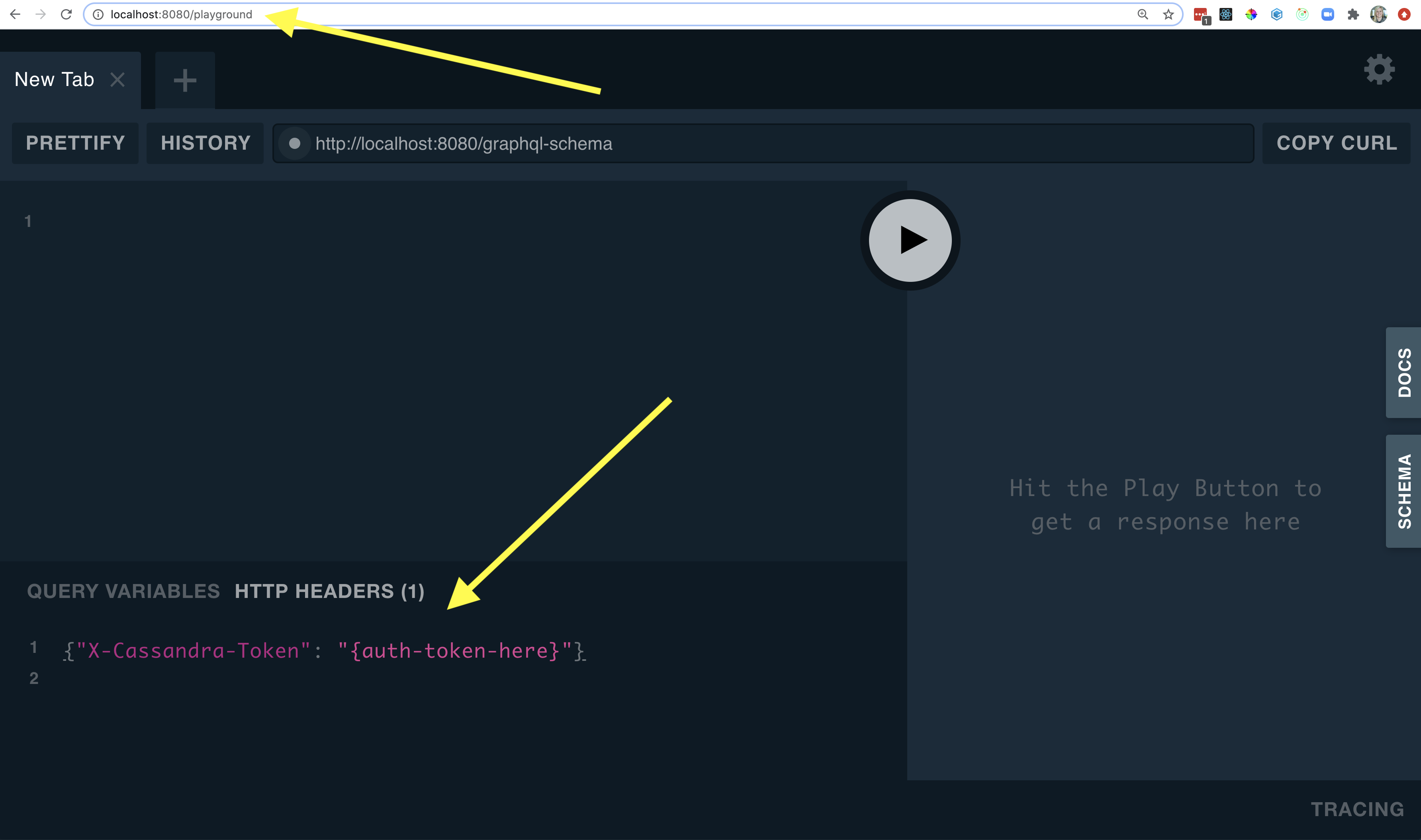
And that is it! You are ready to make tables, insert, and read data. Let’s do that next.
GraphQL + Cassandra: Making Tables and Data I/O
Step 1: Explore the schema API by entering http://localhost:8080/graphql-schema into the playground’s URL field. An example is below:
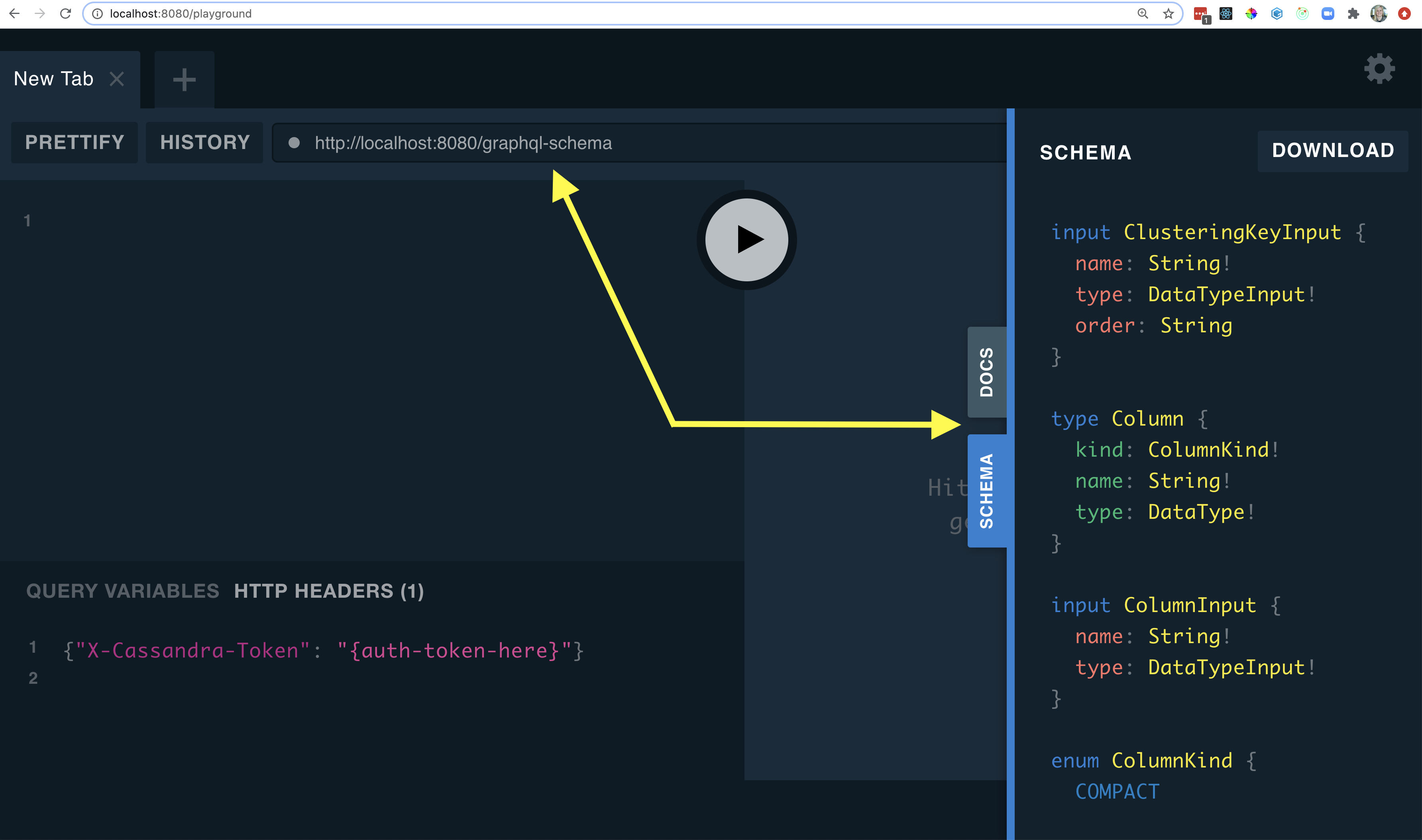
Click on the DOCS and SCHEMA tabs on the right hand side of your screen to see the GraphQL types, mutations, and queries generated by Stargate.
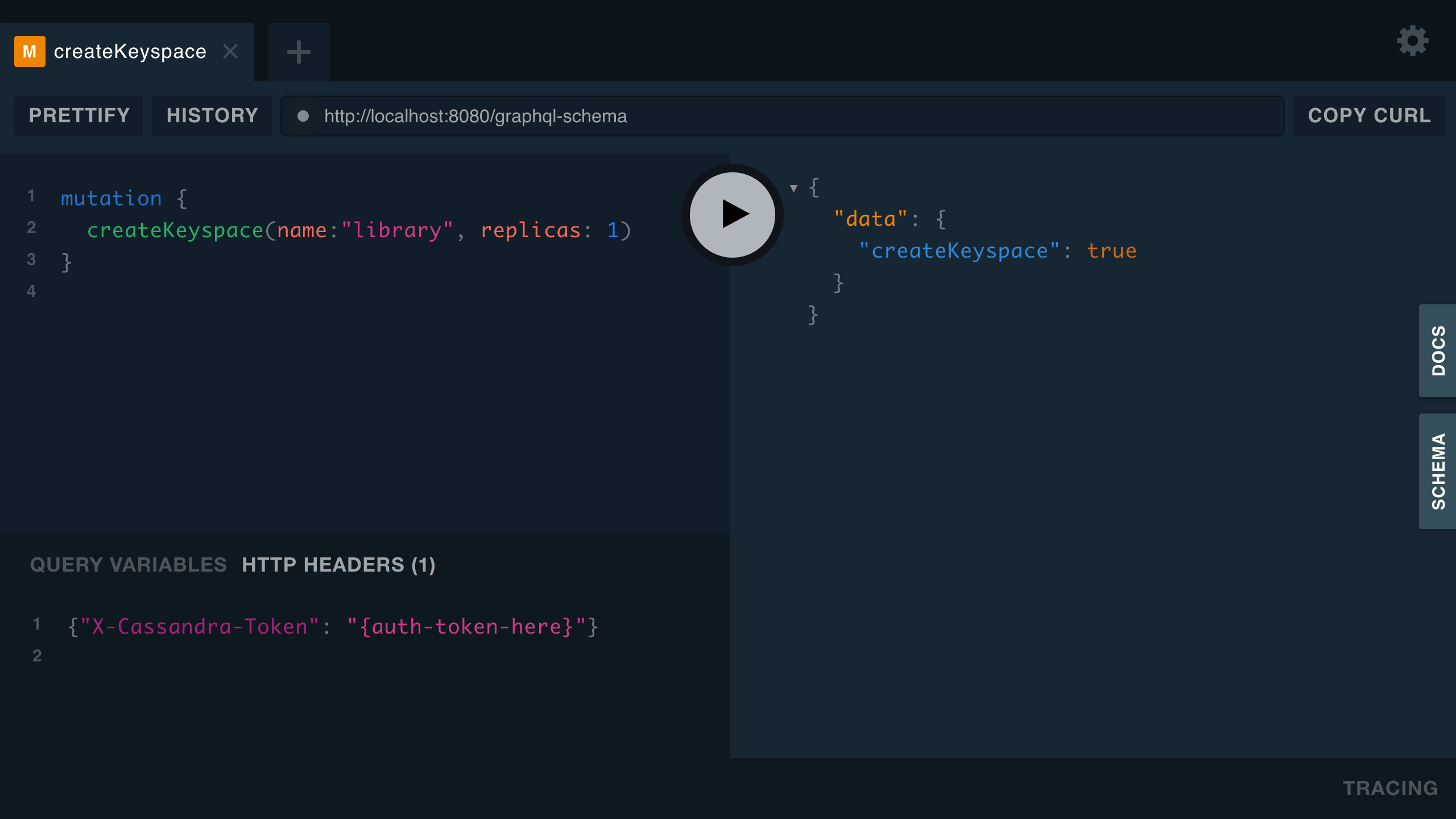
Step 2: Create a keyspace by running the mutation below in GraphQL Playground
mutation {
createKeyspace(name:"library", replicas: 1)
}Expected Output:
Step 3: Create tables by running the mutation below in GraphQL Playground
mutation {
books: createTable(
keyspaceName: "library"
tableName: "books"
partitionKeys: [{ name: "title", type: { basic: TEXT } }]
values: [
# The values associated with the keys
{ name: "author", type: { basic: TEXT } }
{ name: "year", type: { basic: INT } }
{ name: "genre", type: { basic: TEXT } }
]
)
authors: createTable(
keyspaceName: "library"
tableName: "authors"
partitionKeys: [{ name: "name", type: { basic: TEXT } }]
clusteringKeys: [
# Secondary key used to access values within the partition
{ name: "title", type: { basic: TEXT }, order: "ASC" }
]
)
}Expected Output:
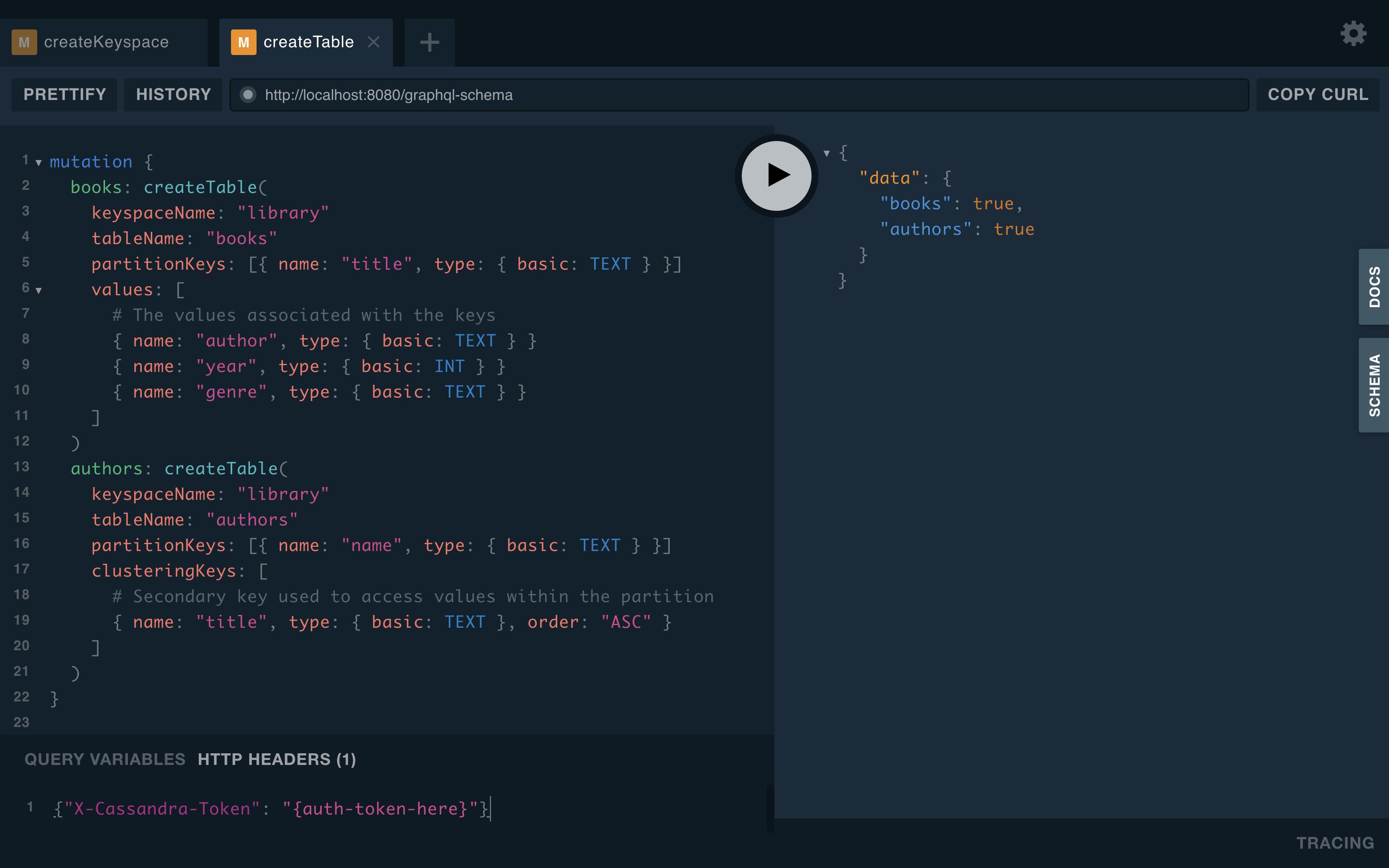
Step 4: Add data by changing the URL in Playground to http://localhost:8080/graphql/library and running the mutation below in GraphQL Playground
mutation {
dune: insertBooks(
value: {
title: "Dune",
author: "Frank Herbert",
genre: "Sci-Fi",
year: 1965
}
) {
value {
title
}
}
}Expected Output:
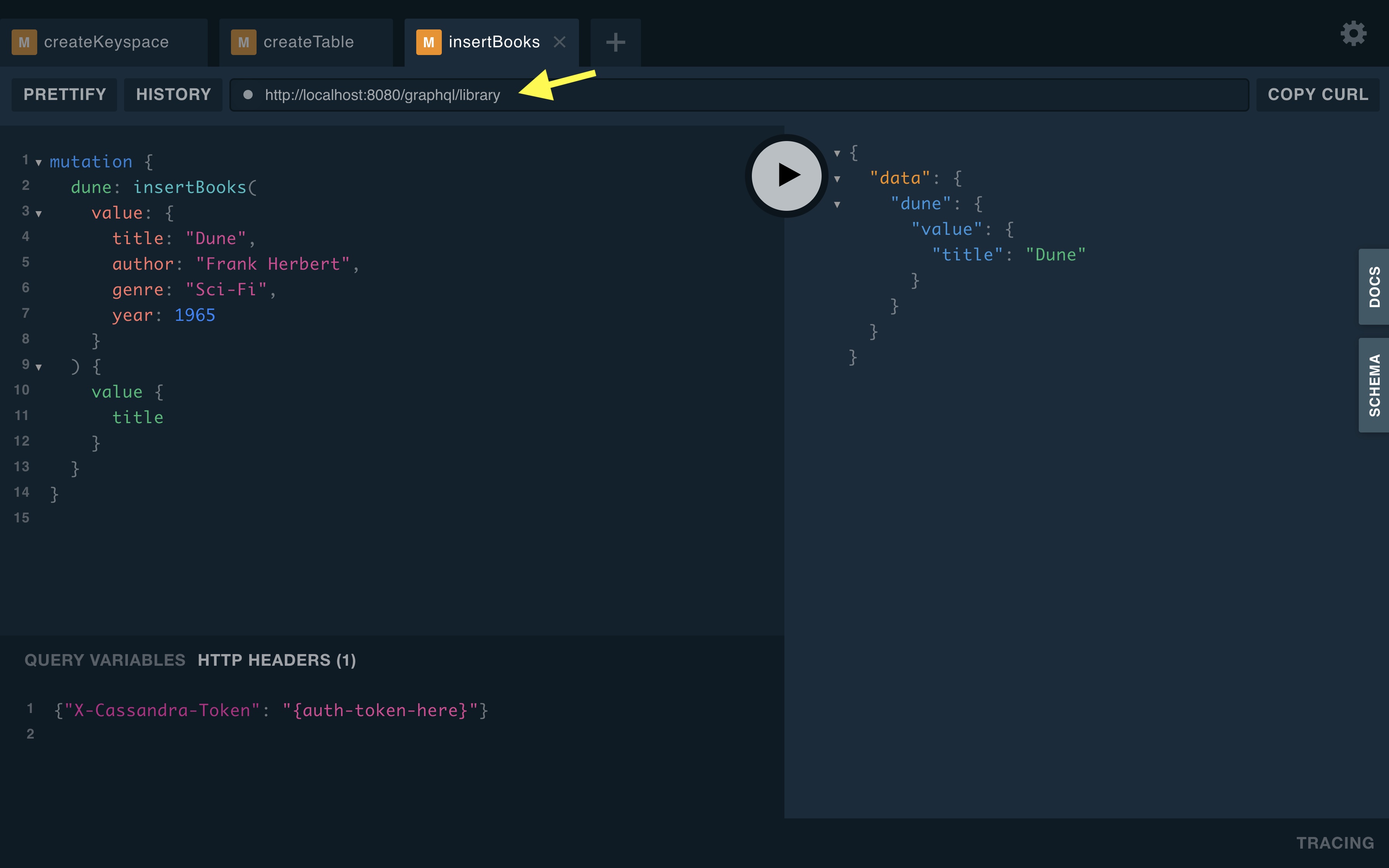
Don’t forget to change the URL in the graphQL Playground to http://localhost:8080/graphql/library
Step 5: Get the data by running the query below in GraphQL Playground
query {
books {
values {
title
author
genre
year
}
}
}Expected Output:
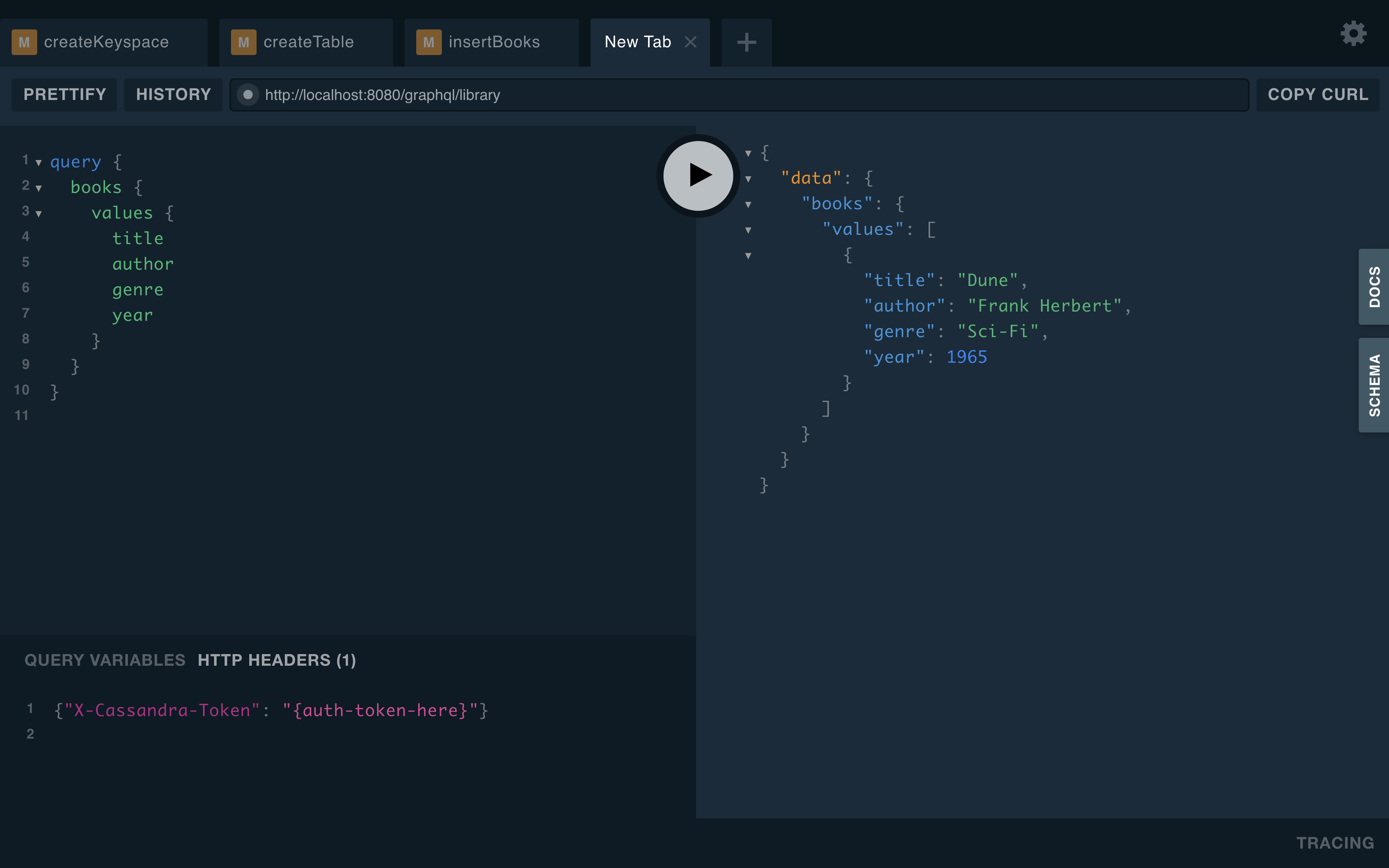
Just like that you have a GraphQL API on top of your Cassandra database. You can find the full reference for this API and more in the documentation.
Deep Dive
Let’s peel back the layers a bit further and talk about a few other aspects of the API. One question that you may ask, what happens when the schema changes? To ensure that Stargate’s GraphQL API stays in sync with the database objects, there are EventListeners that detect the changes and update the KeyspaceHandlers accordingly. This means that if you add/remove tables or change the types of columns, the Stargate GraphQL API will reflect those changes automatically.
The mutations and queries available at the /graphql/{keyspace-name} path work similarly to those at the /graphql-schema path. The available mutations for a single table are insert, update, and delete and correspond to INSERT, UPDATE, and DELETE statements that are available in Cassandra. Each table also has a generated query that allows you to read rows with filtering on the primary key and ordering based on the clustering key. An example of the insert mutation can be found in the documentation:
# insert 2 books in one mutation
mutation insert2Books {
moby: insertbook(value: {title:"Moby Dick", author:"Herman Melville"}) {
value {
title
}
}
catch22: insertbook(value: {title:"Catch-22", author:"Joseph Heller"}) {
value {
title
}
}
}Queries have a filter option available. This filter is useful when you only want to pull back data that fits certain criteria. The filters available include eq (equal), notEq (not equal), gt (greater than), gte (greater than or equal to), lt (less than), lte (less than or equal to), and in (within) operators. Note that these can only be used with fields that were in the primary key during table creation, just like in Cassandra. Here is an example query:
# query a badge record that has a MAP (earned) with the partition key and the clustering key
query oneGold100Badge {
badge(filter: { badge_type: {eq:"Gold"} badge_id: {eq:100}} ) {
values {
badge_type
badge_id
earned {
key
value
}
}
}
}Stargate’s GraphQL API also allows you to have control over the execution of the request with Cassandra. You can set the consistency level for a query to dictate how many data replicas must respond and also the row limit, pagesize and pagestate. All of the normal Cassandra data types are supported.
Next steps
Stay tuned as we continue to iterate on this new GraphQL API and you can follow along by checking out the GitHub issues that are labeled with “graphql”. If there’s anything missing that you think needs to be included, give a 👍 on the corresponding GitHub issue or file a new one if we haven’t captured it.
As always we hope that you’ll join us on this collective journey and feel free to give us a shout on GitHub, our Discord server, or on Twitter @stargateio. We’ll see you in the stars!
 Shoutout to Andrew Regan for the cool visor reflection
Shoutout to Andrew Regan for the cool visor reflection