Init Stargate
We’re excited to release the first preview of Stargate, an open source API framework for data. This project came about because we got tired of using different databases and different APIs depending on the work that we were trying to get done. With “read the manual” fatigue and lengthy selection processes wearing on us every time we created a new project, we thought - why not create a framework that can serve many APIs for a range of workloads? From this, Stargate was born.
For example, if you’re a JavaScript developer building a website, saving and searching JSON is great and maybe you also have some GraphQL sprinkled throughout. If you’re a Java or C# developer working on an enterprise application, SQL is likely more your style. The goal of Stargate is to make your data available for you through whatever API you can dream up regardless of the backing datastore.
So far we’ve started with Apache Cassandra as the first backend and implemented the Cassandra Query Language (CQL) and a REST API for CRUD access to data in tables and have many more APIs coming soon.
For any project to thrive it needs to be easy to work with and contribute to. We kept that in mind while architecting Stargate and the core codebase is modularized to facilitate extensibility and collaboration. We hope that you’ll join us on this journey to redefine what’s possible when it comes to interacting with data at scale and if you’re interested in getting involved you can check out the code on GitHub, join our Discord server, or follow us on Twitter @stargateio! 🚀

How does Stargate work?
Stargate is a data gateway component that is deployed between your client applications and database. We chose Cassandra as the first database because it solves the world’s hardest scale and availability challenges and we think there’s low hanging fruit in terms of APIs for the database.
Stargate itself is based on the concept of a Cassandra coordinator node and is very similar to the “fat client” that Eric Lubow explains in his presentation at Cassandra Summit in 2016. This means when Stargate is deployed, it joins the Cassandra cluster as a coordinator node but does not store any data. We chose this design because coordinator nodes in Cassandra already handle most of the request handling and routing that’s needed for a highly available storage proxy and it made sense to reuse that time-tested logic. This architecture allows for compute to be scaled independently of storage; a common model when using cloud infrastructure.
The high-level architecture diagram below explains where Stargate fits in the stack and the vision for new APIs and integrations.
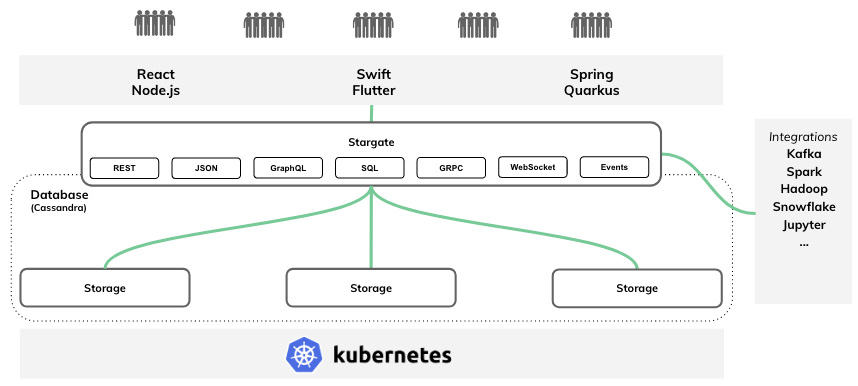
Taking a closer look, when a request is sent to Stargate, it is handled by the API Service, translated to the database query, and dispatched to the Persistence Service. The Persistence service then sends the request to the storage replicas of that row using Cassandra’s internal QueryHandler. The Persistence Service processes the request and responds to the client once it receives acknowledgements from the number of storage replicas specified by the request consistency level.
This is a pretty classic implementation of “Dynamo-based” coordination. Stargate’s ultimate goal is to have pluggable APIs on the front-end and pluggable storage engines on the back-end with all the Dynamo magic happening in the middle.
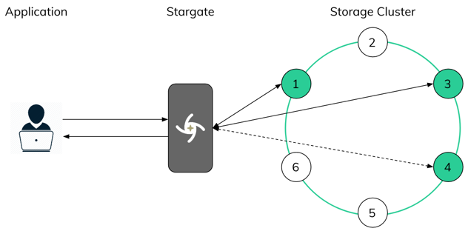
To understand how this distributed coordination works a bit more, in a single 6-node datacenter cluster with 3 storage replicas, an incoming request will go to all 3 replicas that own the requested row. In this case, the nodes labeled 1, 3, and 4 are storages nodes that own the data for the request. In the example below, the consistency level is LOCAL_QUORUM which means that Stargate will read or write data to 2 of the 3 storage replicas in order to satisfy the client request and ack the success.
Get Started
Below is an example of the REST API for CRUD operations that serves the data stored in Cassandra tables over HTTP. You can try this example by downloading Postman and importing the Stargate REST API collection.
Step 1: Pull down the docker image (https://hub.docker.com/u/stargateio)
docker pull stargateio/stargate-3_11:v0.0.3Step 2: Start the docker container using the DEVELOPER_MODE=true env variable. This removes the need to install a separate Cassandra instance.
docker run --name stargate -p 8081:8081 -p 8082:8082 -p 127.0.0.1:9042:9042 -d -e CLUSTER_NAME=stargate -e CLUSTER_VERSION=3.11 -e DEVELOPER_MODE=true stargateio/stargate-3_11:v0.0.3Step 3: Generate an auth token
curl -L -X POST 'http://localhost:8081/v1/auth' -H 'Content-Type: application/json' --data-raw '{
"username": "cassandra",
"password": "cassandra"
}'Expected Output:
{"authToken":"{auth-token-here}"}Step 4: Create a keyspace
curl --location --request POST 'localhost:8082/schemas/keyspaces' \
--header 'X-Cassandra-Token: {auth-token-here}' \
--header 'Content-Type: application/json' \
--data-raw '{
"name": "users_keyspace",
"replicas": 1
}'Expected Output:
{"name":"users_keyspace"}Step 5: Create a table
curl --location --request POST 'localhost:8082/schemas/keyspaces/users_keyspace/tables' \
--header 'X-Cassandra-Token: {auth-token-here}' \
--header 'Content-Type: application/json' \
--data-raw '{
"name": "users",
"columnDefinitions": [
{
"name": "firstname",
"typeDefinition": "text"
},
{
"name": "lastname",
"typeDefinition": "text"
},
{
"name": "email",
"typeDefinition": "text"
},
{
"name": "favorite color",
"typeDefinition": "text"
}
],
"primaryKey": {
"partitionKey": ["firstname"],
"clusteringKey": ["lastname"]
},
"tableOptions": {
"defaultTimeToLive": 0,
"clusteringExpression":[
{
"column": "lastname",
"order": "ASC"
}
]
}
}'Expected Output:
{"name":"users"}Step 6: Add rows
curl --location --request POST 'localhost:8082/v2/keyspaces/users_keyspace/users' \
--header 'X-Cassandra-Token: {auth-token-here}' \
--header 'Content-Type: application/json' \
--data-raw '{
"firstname": "Mookie",
"lastname": "Betts",
"email": "mookie.betts@gmail.com",
"favorite color": "blue"
}'Expected Output:
{"firstname":"Mookie","lastname":"Betts"}Step 7: Get rows
curl -G --location 'http://localhost:8082/v2/keyspaces/users_keyspace/users' \
--header 'X-Cassandra-Token: {auth-token-here}' \
--header 'Content-Type: application/json' \
--data-urlencode 'where={"firstname": {"$eq": "Mookie"}}'Expected Output:
{"count":1,"data":[{"firstname":"Mookie","favorite color":"blue","email":"mookie.betts@gmail.com","lastname":"Betts"}]}Voila! You can find the full reference for the table-based REST API and more in the docs.
How can I get involved?
Check out the code and start building with us! We’ve architected this project with exploration, flexibility, and API and storage agnosticism as our first class citizens; the goal is that this makes it easy for the community to innovate and add new APIs and extensions.
The diagram below shows how the Stargate modules fit together.
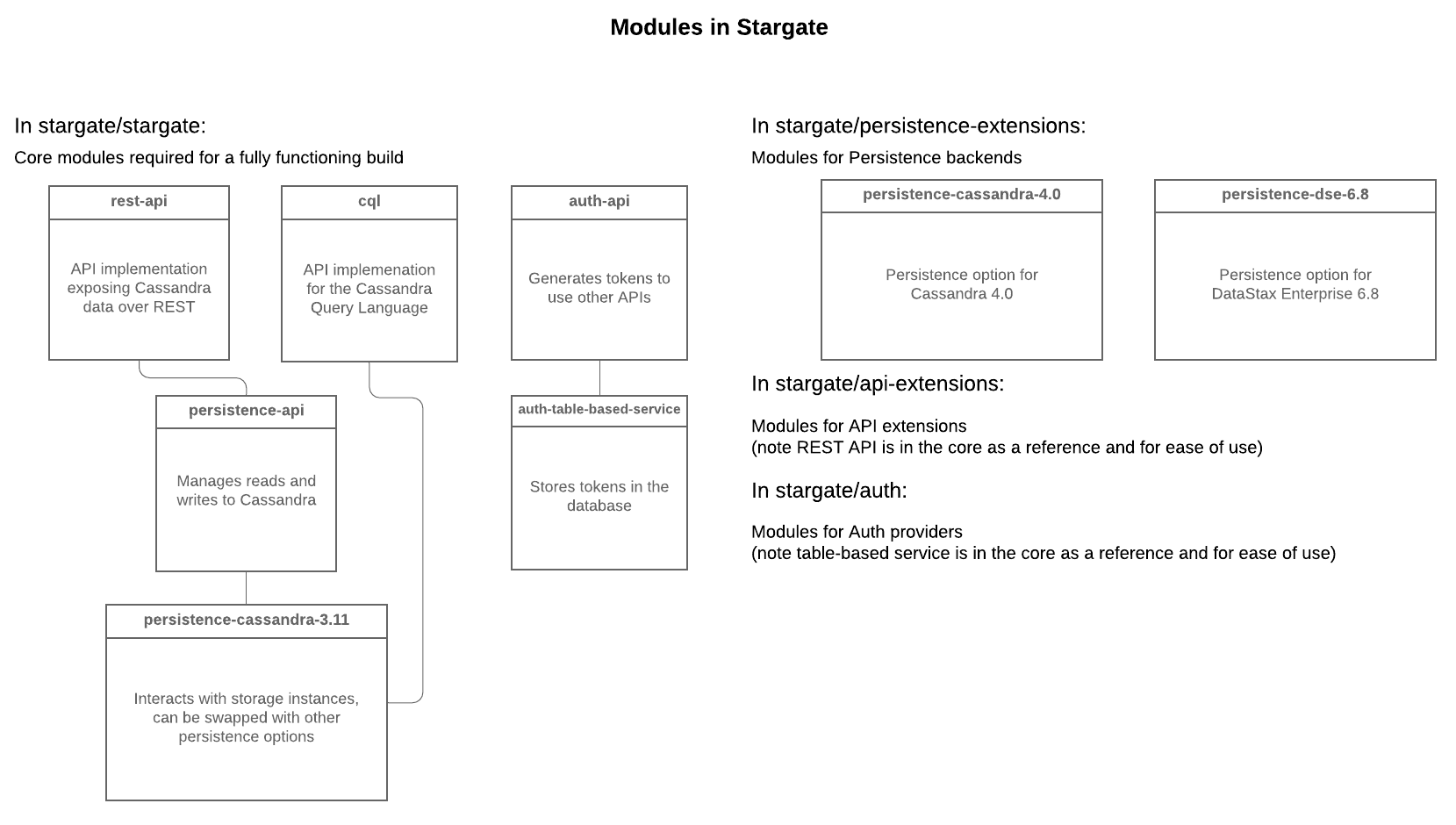
To get started building a new API extension, have a look at the existing REST API implementation in the Stargate repo first. To get started building a new storage extension, check out the persistence-cassandra-3.11 implementation. Once you have an idea of what you want to build, reach out on our Discord server to discuss. Note that the internal APIs are under active development and they are likely to change before the first version is released.
To request new features or file bugs, create a new GitHub issue in the stargate/stargate repository and we’ll take it from there. Let’s Explore We can’t wait to see where this project takes us and we’ll be rolling out a few new APIs in the coming weeks. You can get updates by following us on Twitter @stargateio and throw us a star on Github if you like what you see!
We’re ready for lift-off, see you in the stars! ✨
